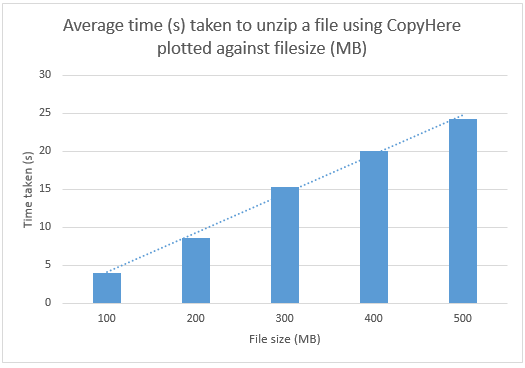
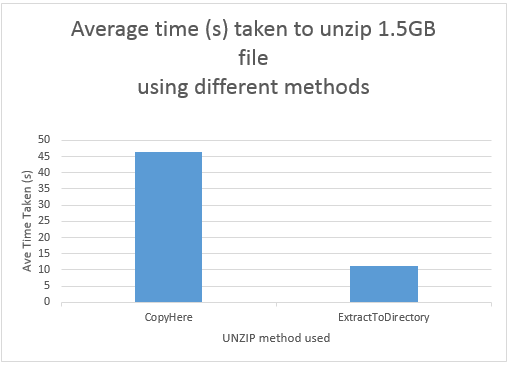
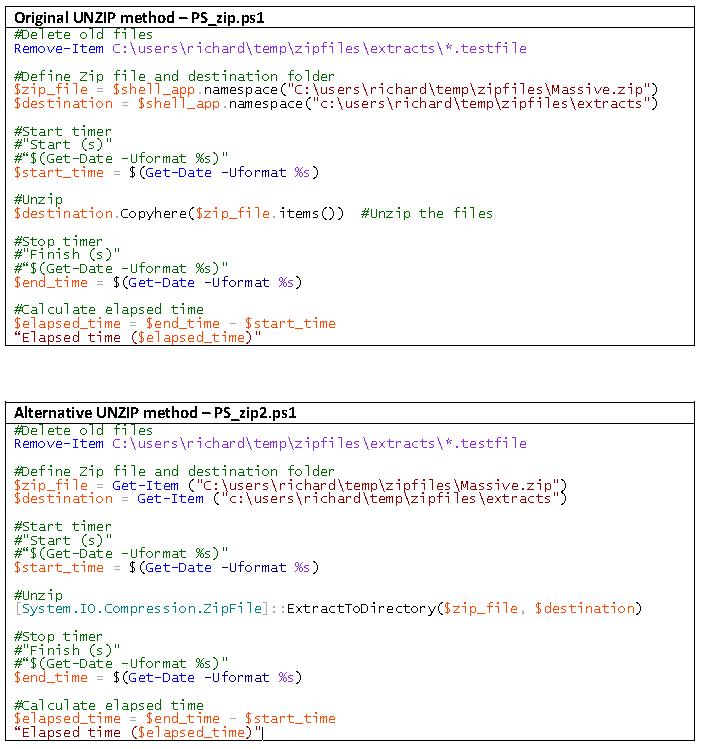
I’m a recent convert to an Android phone and so far I’m really pleased with it. It seems to offer me the flexibility that I want (and didn’t get from my old iPhone). Recently, however I’ve been getting this error message from Google’s Maps application.

This isn’t just a minor annoyance when I’m using the application, it pops up all the time. I presumed that this may be a problem that was only affecting me, but when I saw it on my wife’s Nexus 7, I realised that it must be more widespread.
I had a quick look on the PlayStore and saw that there were a number of comments/complaints about this same problem. I was not alone…..
I decided to try a reinstall, but this isn’t possible for built-in applications. You can uninstall and then reinstall the updates to the built-in application, but that didn’t work for me. The error came back.
The only way to stop the error from occurring is to downgrade Maps to the factory installed version. This is how you do it.
First open Application Manager.
Swipe down from the top of the screen and click the “cog” icon in the top right-hand corner. Then select the “More” tab and press “Application Manager”.
Scroll/swipe until you see the “Maps” application.(like the screen below).

Press “Uninstall Updates”

Press “OK” to confirm that you want to uninstall the updates.
At this point you’ll be warned that the upgraded application will be replaced with the factory version.

Press “OK” and you can revert to using the older version. The application will prompt you to upgrade it from time to time, but you can ignore those prompts to upgrade and restore your phone/tablet to working order.
My only worry is that when the KitKat 4.4 upgrade for Android comes along, it’ll bring with it the newer version of Maps, this could be a reason for holding back on that upgrade until you know that other users are happy with it and that this problem doesn’t reoccur for KitKat users.