Yesterday I was reading this article from TechRepublic which promtped me to write a blog post for Trust IV. I’ve decided to reproduce the article here so that some of my more regular readers might find it.
Browsers have come a long way since Tim Berners-Lee developed his first browser (WorldWideWeb) in 1990. In 1993 NCSA Mosaic became the defacto browser for early adopters of the Internet and this browser is credited with popularising the world wide web. Many of today’s browsers have evolved from this early browser as shown in my simplified* “browser family tree”. (Click image to download .pptx file)

At the heart of each browser is the browser engine. This is the code that takes content from HTML, CSS, JS and image files and displays it on your screen. The browser engine is transparent to most users but it can be important. Changes in browser engine are important for both functional and non-functional testers. Functional testers may come across a website that “works” for one browser and doesn’t work on another browser, or displays different behaviours when tested with different browsers or browser versions. Performance testers may encounter sites that perform well in one browser, but not in another.
This week the Mozilla foundation announced that it was collaborating with Samsung to develop a new browser engine (Servo) to take advantage of the greater performance from multi-core architectures (which are now common in PCs, laptops and even smart phones). At the same time, Google has announced that it will “fork” the Webkit engine (currently used by Chrome, Konqueror and Safari) and develop a new engine (Blink).
Why this matters to testers (and you). Early performance testing was all about making simple requests for page content, then timing how long it took for the web server to respond to the client request. Web pages were often static, and rendered quickly in either IE or Firefox (the prevalent browsers from year 2000 onwards). Internet connections were slow and the bulk of the time that a user spent waiting was download time.
Nowadays things are different. Multiple browsers are available (some optimised for mobile use). This means that the same web server may serve different content based on browser version. Some users are likely to be on high speed internet connections and others will be using 3G or Edge on a mobile device. As the number of browsers increases it is still possible to test in “the old way” but testing in this way is becoming increasingly less valid. I often find that my clients are interested in realistic page response times for users, rather than simply the time taken to download content.
For example, I used a private instance of WebPageTest to measure the page response time for the TrustIV website. For a new user with no cached content the page downloaded in 1.8 seconds but the page was not visually complete (from a user perspective) until 2.9 seconds had elapsed. Which of these response times would/should I report if this were a performance test?
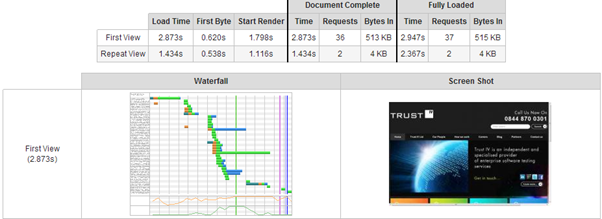
With low end performance test tools, all I could report on are the page download times. This is fine in many cases where a period of iterative testing is carried out to improve performance and find bottlenecks. But what if there’s a problem in client-side code? Unless my test tool takes the time to render the content I’ll be mis-reporting true end-user performance to the client.
Choosing a test tool
Some of the higher end performance test tools such as LoadRunner, SilkPerformer, SOASTA and NeoLoad render content using one or other of the browser engines. This gives an indication of true page load times, but not all test tools can do this. It’s important to fully understand your client’s browser types and the limitations of your test tools before you try to advise your customers on probable end-user response times. This is even more true now that there are 6 browser engines “in the wild”, rather than the 4 that we knew about last week.
I’m looking forward to hearing from the major test tool vendors about how they’ll adapt their test tools now we’re at yet another “fork in the road”.

*I based my “browser family tree” on information from a number of sources including the Wikipedia “timeline of web browsers” and the wonderful interactive graphic from “evolution of the web”



