My followers on Twitter and LinkedIn will already be aware that I went to the HP Discover conference in Las Vegas last week. They’ll have heard tales of lost baggage, extreme “jet-lag induced tiredness” (body-clock waking me at 3:30 every morning) as well as various updates from the conference.
People go to the conference for a variety of reasons; to hear the keynote speeches, attend NDA sessions, see application demonstrations or to meet HP product managers,R&D teams or other experts. I’ve been part of Vivit for over 4 years now and before that I was a member of the Mercury software user group. For me the highlight of my conference was meeting up with a group of fellow testers one evening over a glass or two of whisky (thanks Mr Moore)
Left to Right. Wilson Mar, Scott Hysmith, James Pulley, Richard Bishop, Scott Moore
These testers have inspired me from my first days as a tester when I used to frequent Wilson Mar’s website and Scott Moore’s loadtester.com. I knew James Pulley through his moderation of Google, Yahoo and StackOverflow LoadRunner groups and more recently I’ve been listening to James Pulley and Mark Tomlinson’s PerfBytes podcasts.
I sincerely hope that this becomes a regular event at conferences. It was great to finally meet these people face to face and “put the testing world to rights” 🙂
Yesterday I was reading this article from TechRepublic which promtped me to write a blog post for Trust IV. I’ve decided to reproduce the article here so that some of my more regular readers might find it.
Browsers have come a long way since Tim Berners-Lee developed his first browser (WorldWideWeb) in 1990. In 1993 NCSA Mosaic became the defacto browser for early adopters of the Internet and this browser is credited with popularising the world wide web. Many of today’s browsers have evolved from this early browser as shown in my simplified* “browser family tree”. (Click image to download .pptx file)
Browser evolution
At the heart of each browser is the browser engine. This is the code that takes content from HTML, CSS, JS and image files and displays it on your screen. The browser engine is transparent to most users but it can be important. Changes in browser engine are important for both functional and non-functional testers. Functional testers may come across a website that “works” for one browser and doesn’t work on another browser, or displays different behaviours when tested with different browsers or browser versions. Performance testers may encounter sites that perform well in one browser, but not in another.
This week the Mozilla foundationannounced that it was collaborating with Samsung to develop a new browser engine (Servo) to take advantage of the greater performance from multi-core architectures (which are now common in PCs, laptops and even smart phones). At the same time, Google has announced that it will “fork” the Webkit engine (currently used by Chrome, Konqueror and Safari) and develop a new engine (Blink).
Why this matters to testers (and you). Early performance testing was all about making simple requests for page content, then timing how long it took for the web server to respond to the client request. Web pages were often static, and rendered quickly in either IE or Firefox (the prevalent browsers from year 2000 onwards). Internet connections were slow and the bulk of the time that a user spent waiting was download time.
Nowadays things are different. Multiple browsers are available (some optimised for mobile use). This means that the same web server may serve different content based on browser version. Some users are likely to be on high speed internet connections and others will be using 3G or Edge on a mobile device. As the number of browsers increases it is still possible to test in “the old way” but testing in this way is becoming increasingly less valid. I often find that my clients are interested in realistic page response times for users, rather than simply the time taken to download content.
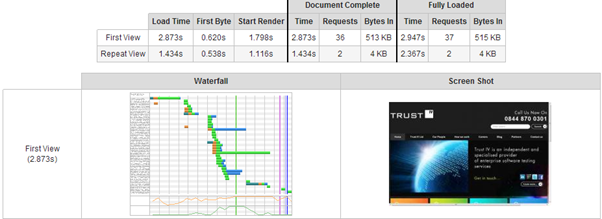
For example, I used a private instance of WebPageTest to measure the page response time for the TrustIV website. For a new user with no cached content the page downloaded in 1.8 seconds but the page was not visually complete (from a user perspective) until 2.9 seconds had elapsed. Which of these response times would/should I report if this were a performance test?
With low end performance test tools, all I could report on are the page download times. This is fine in many cases where a period of iterative testing is carried out to improve performance and find bottlenecks. But what if there’s a problem in client-side code? Unless my test tool takes the time to render the content I’ll be mis-reporting true end-user performance to the client.
Choosing a test tool
Some of the higher end performance test tools such as LoadRunner, SilkPerformer, SOASTA and NeoLoad render content using one or other of the browser engines. This gives an indication of true page load times, but not all test tools can do this. It’s important to fully understand your client’s browser types and the limitations of your test tools before you try to advise your customers on probable end-user response times. This is even more true now that there are 6 browser engines “in the wild”, rather than the 4 that we knew about last week.
I’m looking forward to hearing from the major test tool vendors about how they’ll adapt their test tools now we’re at yet another “fork in the road”.
*I based my “browser family tree” on information from a number of sources including the Wikipedia “timeline of web browsers” and the wonderful interactive graphic from “evolution of the web”
I wasn’t surprised to read an article on the BBC news website explaining that UK banks (and more importantly their customers) are likely to experience more “software glitches” in 2013. The likelihood of problems increases as systems age, experienced technicians leave through free-will or redundancy and corners are cut to meet project deadlines.
I was surprised however, to read the term “technical debt” in the mainstream press. Normally this term is consigned to the “geek world”. Technical debt builds up in computer systems for a variety of reasons, as outlined in the article.
Increased complexity of systems This is exacerbated by mergers and demergers which force IT systems, never designed to co-exist to be “made compatible” with each other”. Rather than rewriting code, or migrating to a new shared platform designed specifically for the purpose, a sticking plaster approach is taken. This works in the short term but increases system complexity (and risk) in the long term.
Under-investment and a lack of modernisation
Rather than invest in upgrades, the “if it isn’t broke, don’t fix it” mentality is allowed to predominate. This is sensible in the short term but builds up problems for later.
Outsourcing
It’s harder to modify somebody else’s code than changing your own. As well as this, after outsourcing or off-shoring becomes entrenched in your organisation your in-house teams may lack the skills to do this work. This leaves you more reliant on the external contractor than would be desirable.
Technical debt, like other debts needs to be paid in the end and unfortunately UK banks are finding this out the hard way. The well-documented, recent problems with Faster Payments, NatWest batch jobs and Knight Capital’s trading errors will be the tip of the iceberg. There will be a significant number of “near misses” that go unreported.
Testing, why bother?
The article goes on to mention testing and says that “Modern computer systems are so complicated you would need to perform more tests than there are stars in the sky to be 100% sure there were no problems in the system”.
This may be true, but all testing is important and good testing can (and does) flush out problems that otherwise can go on to cripple banking systems. This leads me on to another major risk factor for banks and other sectors.
Who is doing your testing?
School children aren’t allowed to mark their own homework, so why do you allow your IT project teams to do it? Testing best practice says that the test team should be separate from the development team. This helps to prevent problems from being brushed under the carpet by a development team that is desperate to get their code deployed so that they can move onto the next project or invoice the customer.
Agile development methods have tended to merge testing and development teams (for good reasons). Testing becomes an inherent part of the software development work, reducing the likelihood of big problems at the end of a project.
Having said that, in my opinion; regardless of your development techniques it is vital to get at the very least an independent review of your tests. Ideally a separate team should complete your testing. Otherwise you can’t even start to quantify the technical debt building up within your systems.