…Sadly this is too good to be true.
Today I received a WhatsApp post in a group representing a sports team that my daughter plays for. It had a convincing picture of a Cadbury’s hamper and said that Cadbury’s were giving everyone in the UK some free chocolate to help improve morale during lockdown.
Apart from the fact that the UK population could probably bankrupt Cadbury’s by taking them up on this offer, here are a few reasons that the link should have raised alarm bells.
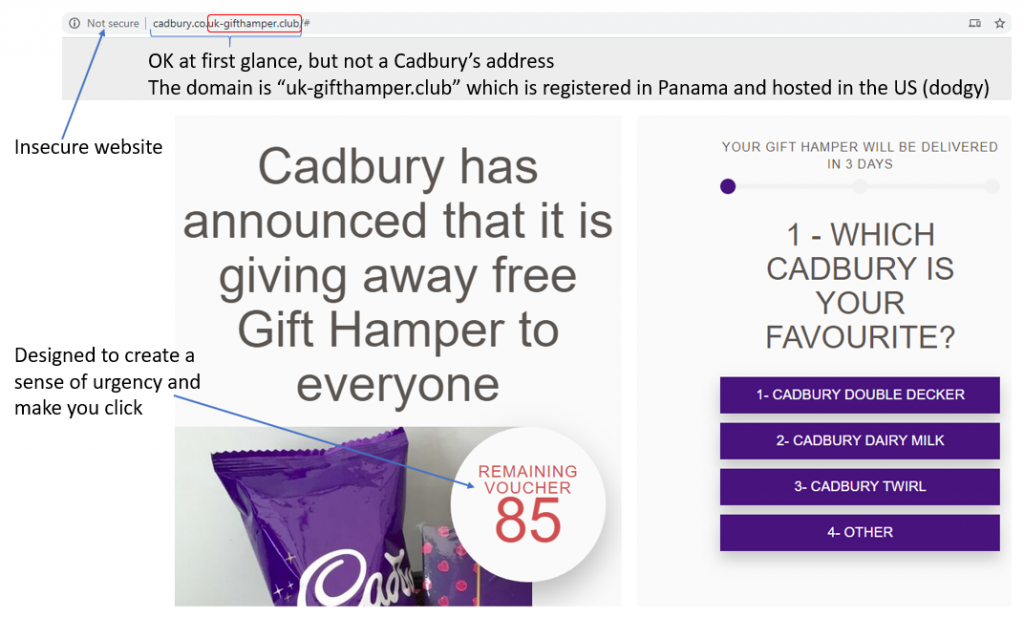
- The address bar in the browser shows that the website is insecure.
Any large corporate like Cadbury’s or their PR agency would use a secure site.
(You can identify secure sites by the fact that they have a padlock next to them). - If you click in the address bar, you can see that the address starts with “http://” rather than “https://”
- At first glance the address looks OK. (It’s been designed to look that way).
It includes the “cadbury.co.uk” and “giftclub” but if you think carefully about the address you can see that the domain is “uk-gifthamper.club”. - If you start to get “a bit geeky” and look into the domain register to see who owns that domain it starts to look even more suspicious.
I looked on EuroDNS.com which I know has a global domain search facility. https://www.eurodns.com/whois-search/global-domain-name
This shows that the domain was only registered a couple of days ago in Panama. No registrant name or contact details are listed.

Sadly there’s no such thing as a free lunch, this is likely to be an update to an old hoax circulating on the Internet and reported on by HoaxSlayer.
Additional info:
https://www.hoax-slayer.net/cadbury-free-basket-of-chocolate-facebook-scam/